Storing Sortable Items in a Relational Database
Represent drag & drop sorting in SQL: Integer gaps, JSON fields, Lexorank, & buckets. Explore efficient solutions for reordering list items in relational databases. Learn the trade-offs


Hey there! How is it going? Last week working with Bezier I faced a problem that I have never seen before and after a moment of thought, I reached out to a solution that I want to expose today in order to help others to solve this situation.
Problem
Imagine you have a drag and drop sortable list like the next one where you can arrange the items in the order you prefer.

Now then, we are using Cloudflare D1 as storage service, so we have to solve this using a relational database (SQLite) and a short number of read/write operations in the database to keep costs low.
Despite the application is offline first, real time synchronization is very important for the feature so we have to put the changes on the database as soon as they are made.
With this problem, have you already found a solution?
The First Solution
The first solution was a little bit trivial. Just add a new field position starting from 0 to N, and if you want to move the element j to the position i, update the elements in the range [min(i, j), max(i, j)) to set the new positions.
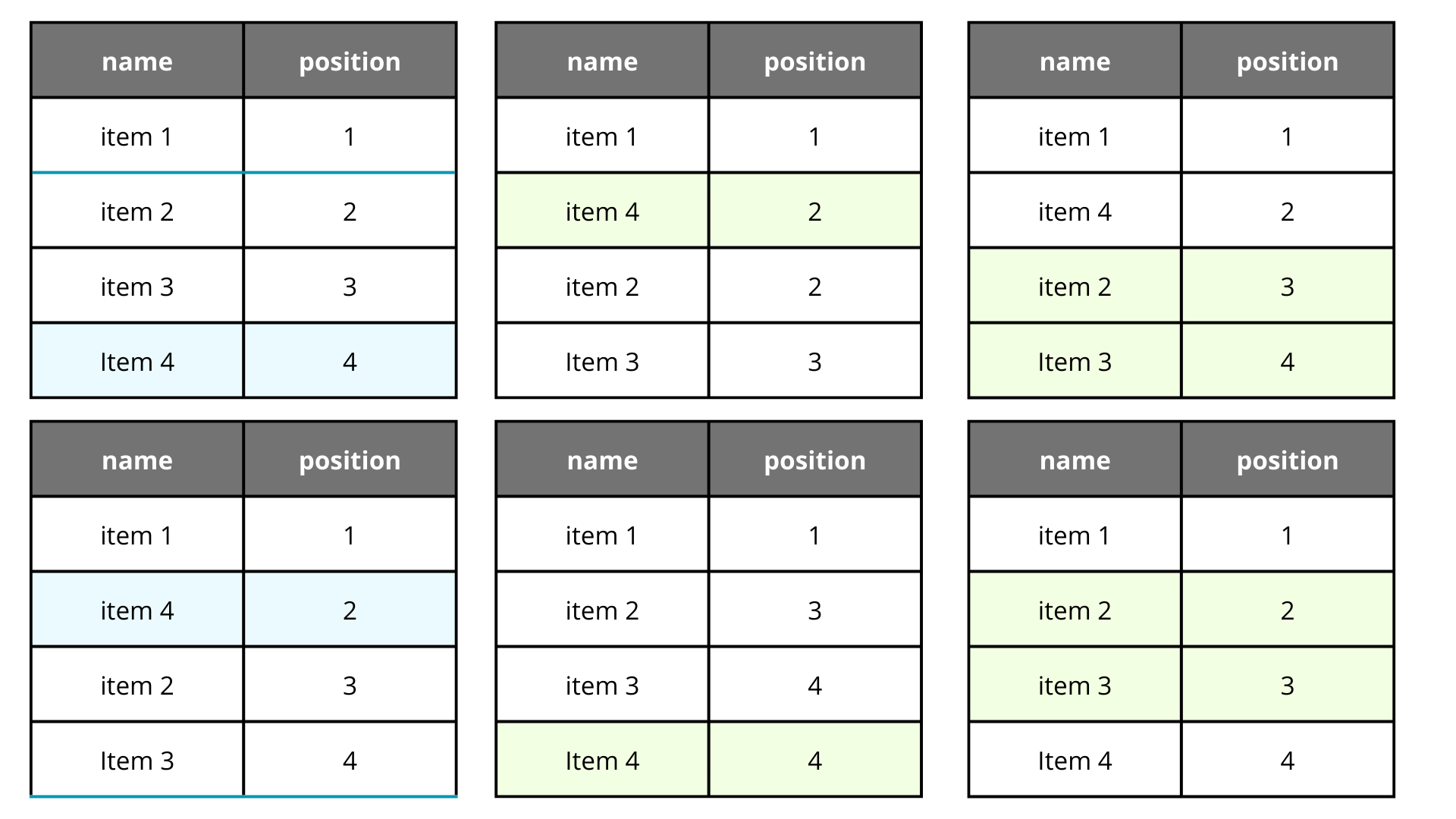
Nothing out of the ordinary, this would be a classical insertion algorithm. The problem with this approach is that for each change in the database we have to update a lot of records, so it will result expensive pretty soon.
The Linked List Solution
What about linked list? Create a next/prev cursor to the next and prev id, and if you want to reorder, just update 5 records, to get your new order.
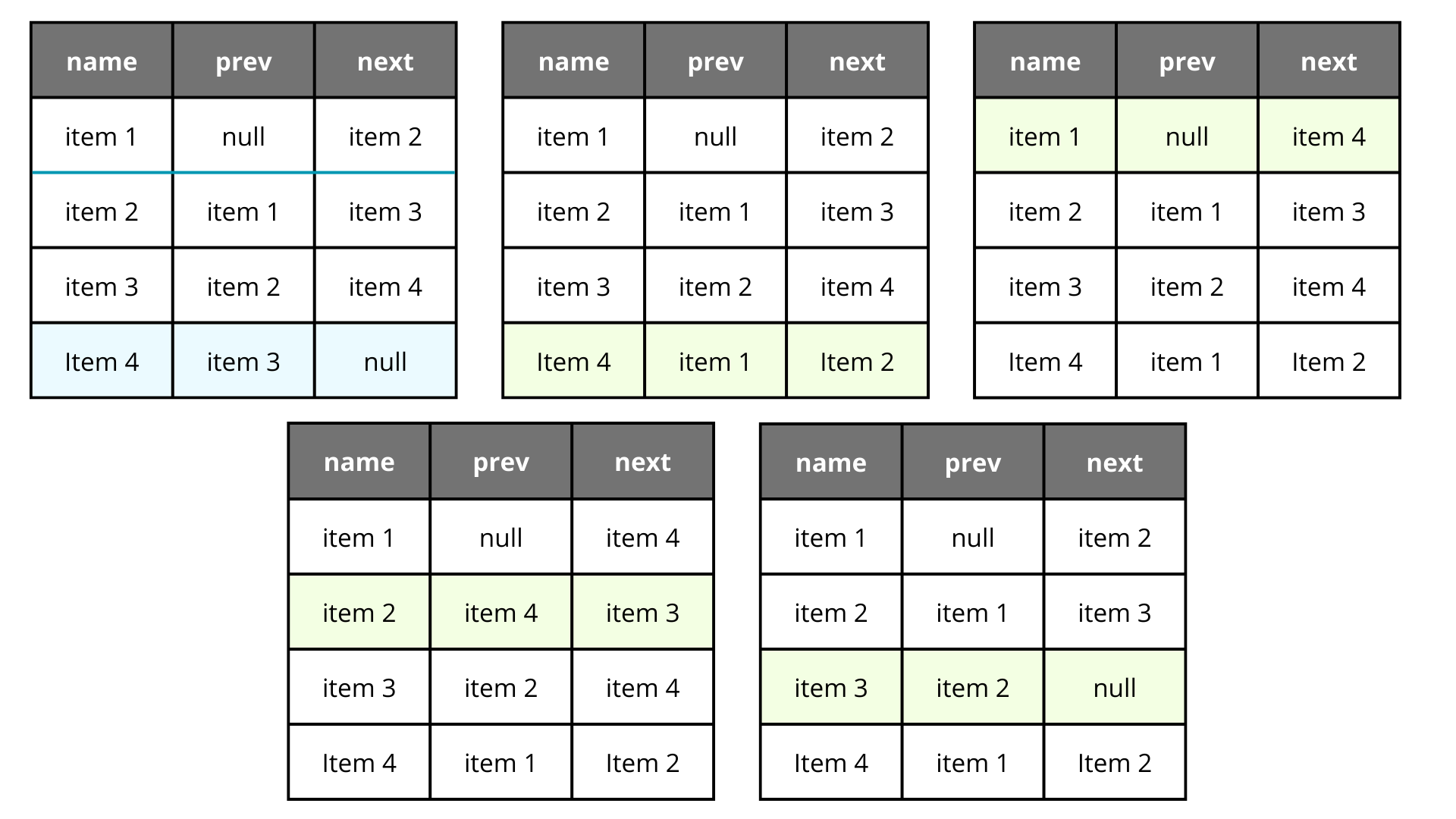
It definitely is better and more predictable than the other approach, but it still affects many rows, is not as easy to understand as the last one, and can lead to integrity issues in a concurrent software.
The JSON Field
I see. The problem is SQL, but if you use a Document-based or Graph-based database solution this will not happen. Why not using a JSON field to store the items instead of using rows of a relational database?

This definitely could be a solution, but it does not work for my use case because my items also have relations and queries to operate with them, I just cannot break that and put everything inside a field. Anyways, I have to say that this is a valid solution and I think if there would be no better solution I would opt for this one.
The JSON Order Field
Ok. So if the relationship of the database matters, why we just don't decouple the order from the model and create a new field just for the order of the list that contains an array of the ids in the order they will be rendered?
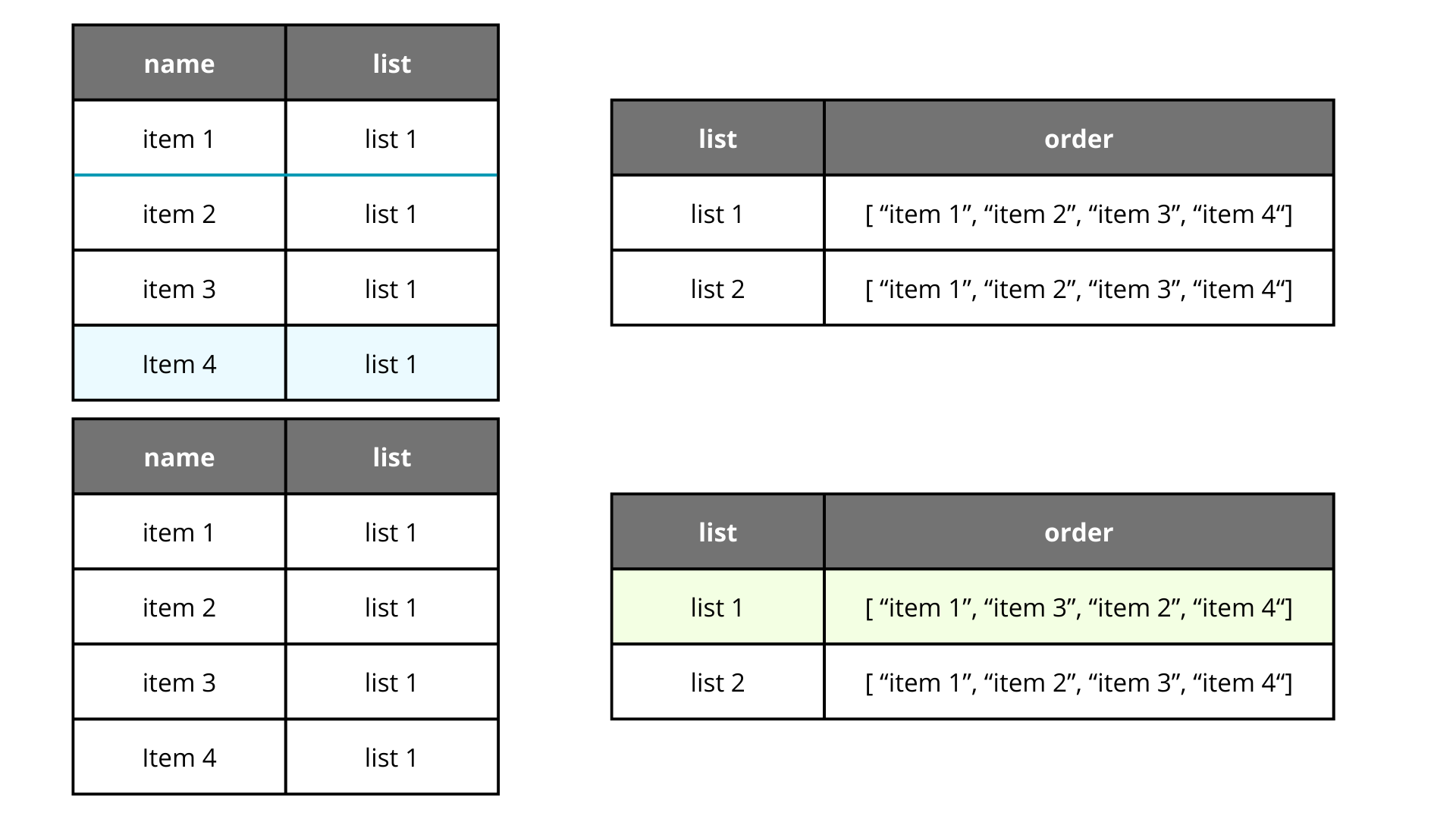
This solution makes sense, solves the problem, and just updates a single field. It is perfect, isn't? I guess, I am pretty sure that there are no perfect solutions, just optimal, and for this case maybe this is a nice solution, but what about if we want to include nested items? We can solve it, but perhaps we will have to break the functionality and migrate records. I don't know, I just didn't felt comfortable with this approach, but perhaps this is enough for you, so it worth a mention!
The Integer Gap Solution
Let's go back to the first solution. The problem with that solution was that we had to update all the records in a range just to update a single position. But what if we do not use a sequential order 1 by 1, and if we decide to use a gap between orders?
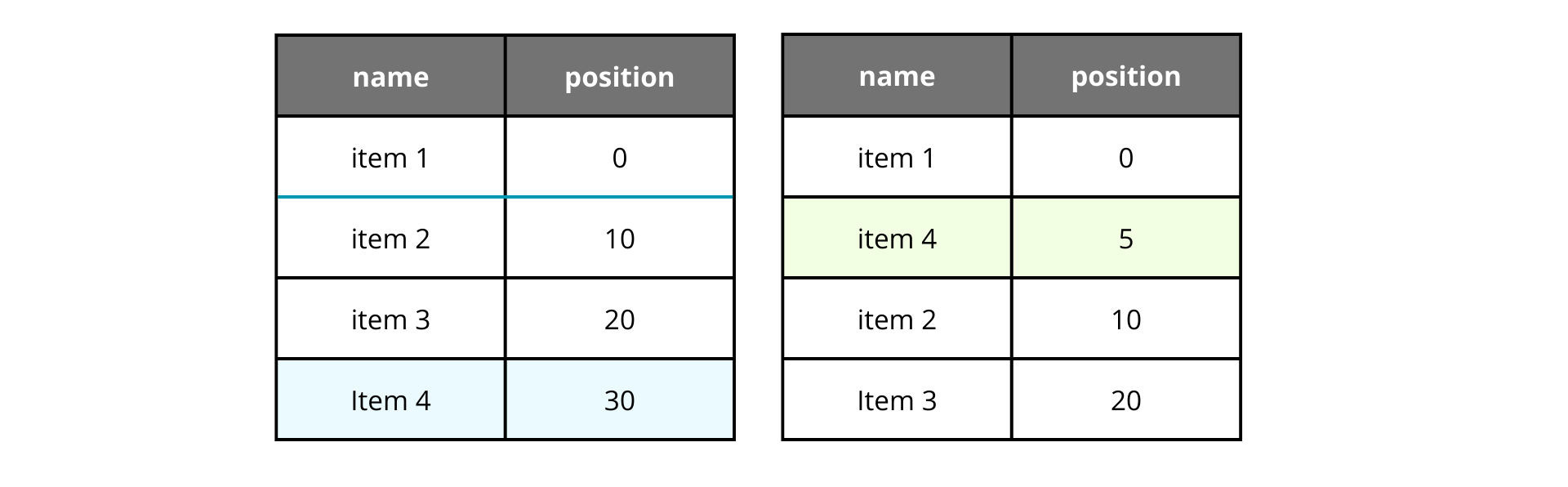
If we want to move an item, we calculate the middle point between the items we want to insert, and change the position to that element. It seems working as a charm, but there is a big problem here, let's move the item 2 to the second position again.
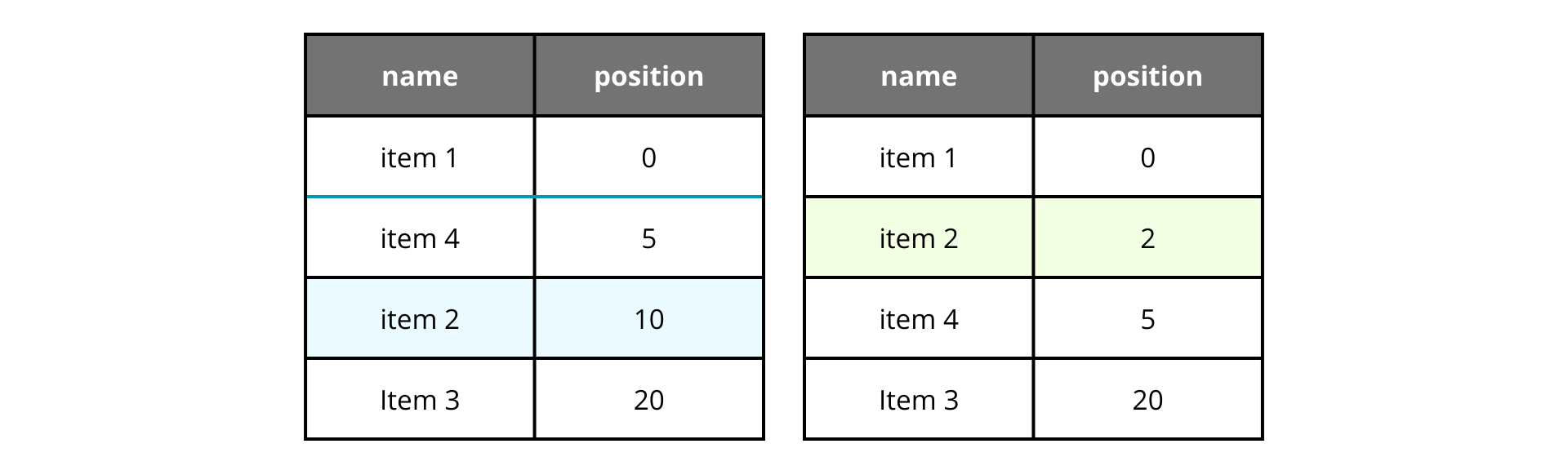
You see? After moving the item 2 to the second position again the position field reduced drastically to 2, that means we only can introduce a single element in between item 1 and item 2 despite we decided to use a great gap of 10.
The Real Gap Solution
We have the last problem because integer numbers are finite between intervals, there are no integers between 0 and 1, but real numbers are infinite, why not use them instead?
The reason is this solves nothing in the short time, it just delays the problem perhaps 10 - 15 sorts before facing it again. Real numbers are infinite in the math world, but computers have a limit determined by the bits. We have another solution.
The Lexorank Solution
But who told us that we have to work with numbers? Who forced us to use base 10 numbers? Why not use text fields instead with letters and numbers and sort them alphabetically?
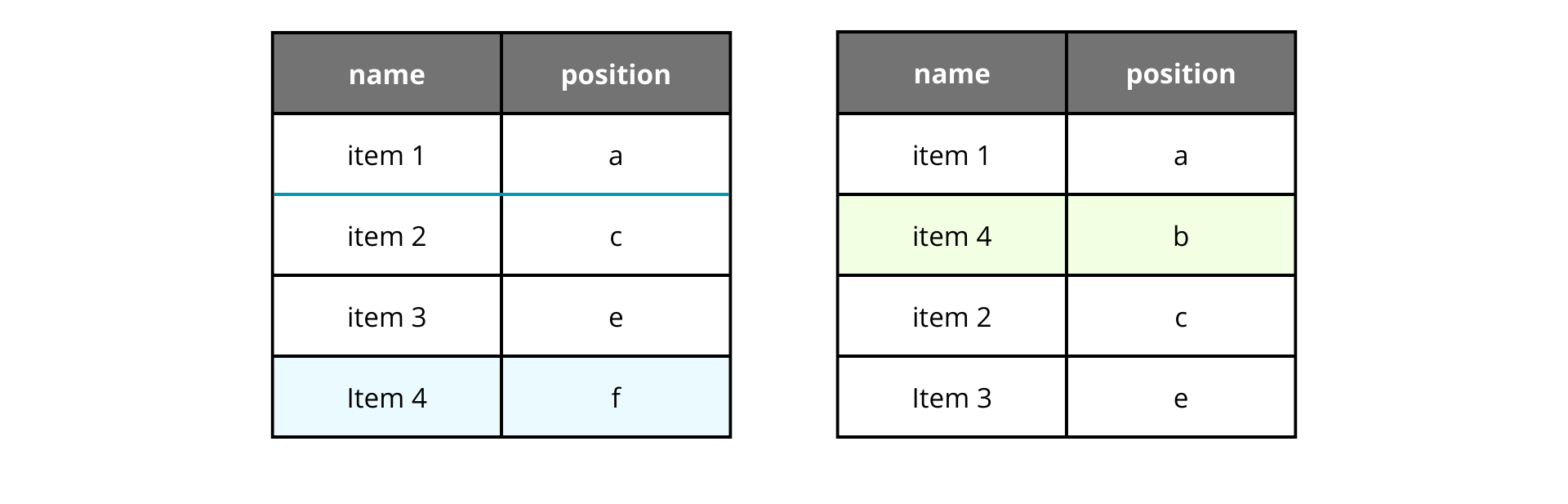
As we can see it does work, but with one letter it makes no sense since the gaps are determined by the difference between them, so a gap will never be lower than the gap between characters and we will face the problem we had with all the gaps methods.
And we are almost reaching our solution. If we decide to use more letters, those gaps will become greater and greater. Let's test with two characters.
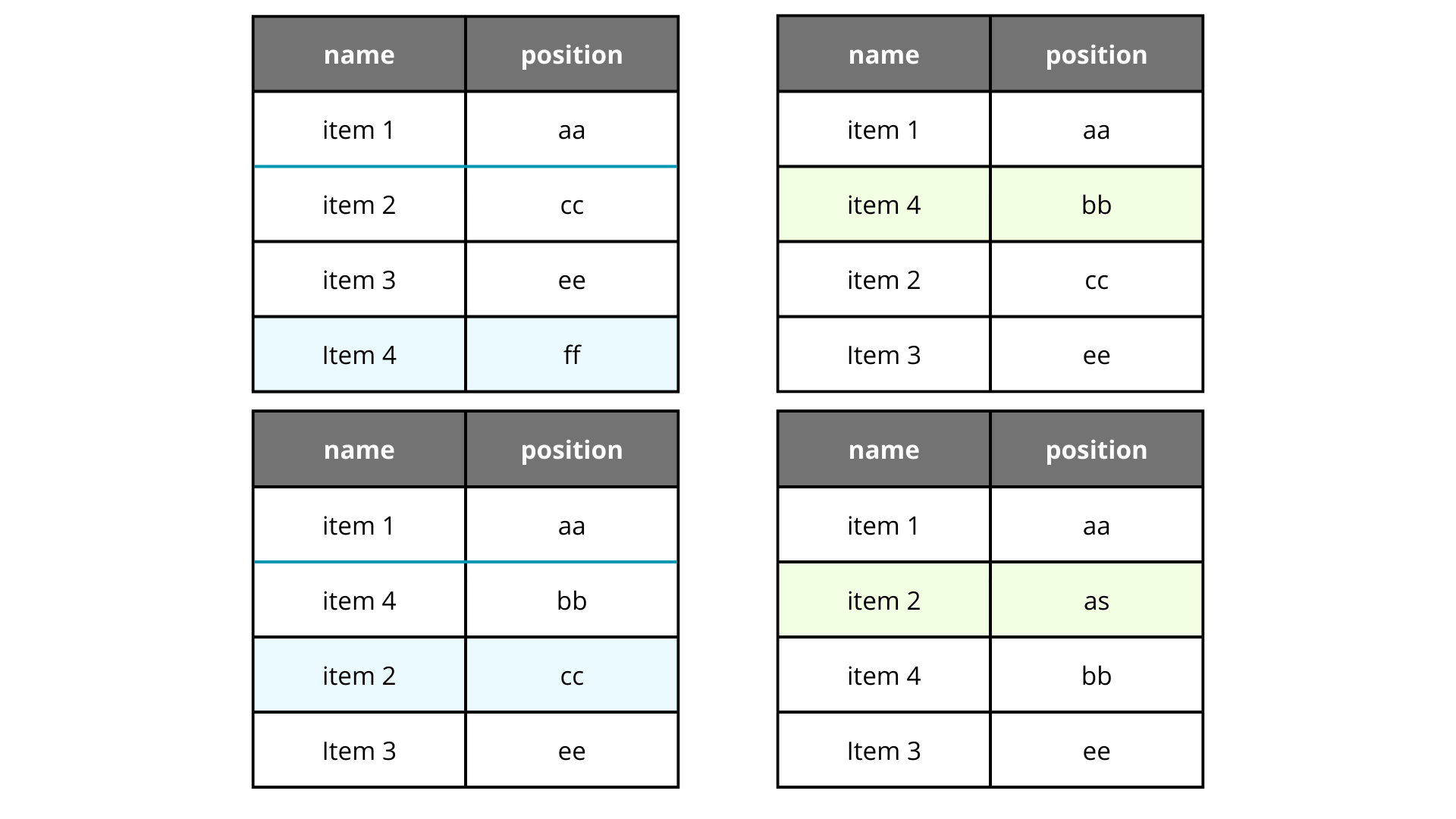
Awesome, isn't? Just adding a new character we could add a lot of new gaps with no problems. So, the final answer to solve this problem is adding more characters, but obviosly there is still a small problem, the number of sorts is not infinite, we will reach a point where we have no gaps eventually, maybe 100-1000 movements, it stills fail!
For this we can go for two solutions, or using both.
We could rebalance every time the ranks of the database, e.g. setting the positions to a nice gap every 12 hours which require a lot of reads and writes every day but guarantees long gaps to put elements.
The other solution - Introduced by Jira - are the buckets. Buckets are prefixes that help to identify the elements that are being sorted at a given time, kind of a container. When a rank surpasses a certain threshold a rebalancing process start, adding all the elements to a new bucket with the new ranks.
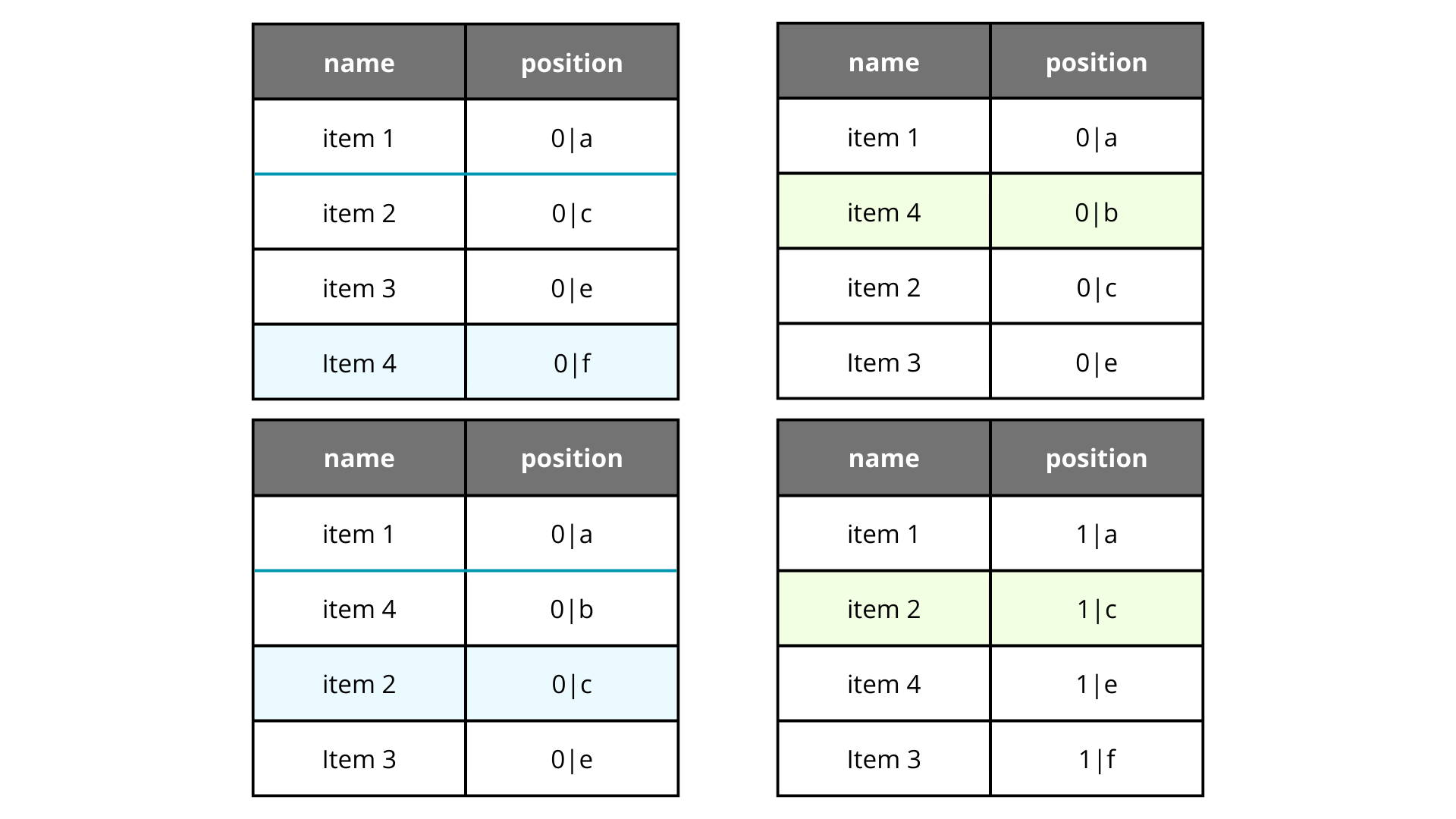
As you can see in the example, we have a bucket 0, when we try to move an element to a rank that cannot be set, we move all the elements to the bucket 1 and reset the gaps.
For my project, the bucket alternative was enough because this type of overflow with 6 characters is something strange, almost impossible, and if it happens will only affect the records of the list that needs it. For you project, you could decide to use both approaches, and update the ranks every certain time meanwhile you balance the boundary cases with buckets.
The Bottom Line
We already reviewed many of the approaches I visited during the development of my project. There are no solutions better than others and you may decide to go with one or another depending of your use case.
If you enjoy the content, please don't hesitate to subscribe and leave a comment! I would love to connect with you and hear your thoughts on the topics I cover. Your feedback is greatly appreciated! Leave a tip.