How to Create a Programming Language
Creating a programming language. Language interpreter. Abstract Syntax Trees (AST) and ANTLR4 example with StepCode a pseudocode programming language


Two years ago, I was teaching Algorithms and Programming. We used pseudocode a lot because it's fantastic for focusing on the logic without getting tangled in the strict rules of, languages like Java or C++. But there was always an small problem...
My students would diligently write out their algorithms in pseudocode, mapping out loops and conditions, really thinking through the steps, but then they had no easy way to actually run it. How do you know if your carefully crafted pseudocode logic actually works? How do you test edge cases? How do you debug it? It felt like teaching someone to describe a recipe perfectly but never letting them cook it.
So, I thought, "What if they could run it? What if pseudocode wasn't just static text on a page?" That's where the idea for StepCode sparked. I decided to build a tool (an interpreter) specifically for the kind of pseudocode we were using. And crucially, I wanted it to be super accessible. No complicated installs, no environment setup headaches, just run it right in the web browser of any device with access to Internet.
In this blog post we will see how you can create your own programming language like StepCode, by defining it, creating the syntax, executing the lexing and parsing, and interpreting the language so it can be understandable by the machine.
Defining Its Nature
Before writing a single line of code for the language interpreter, you have to figure out the language itself. What problem is it solving? Who is it for?
For StepCode, the "why" was clear:
- Education: Make it easier to learn fundamental programming concepts (loops, conditions, variables) without wrestling with the picky syntax of languages like C++ or Java right away.
- Accessibility: Offer a smoother path for Spanish speakers by allowing keywords in both English and Spanish. Think
IFandSI,WHILEandMIENTRAS.
With the "why" settled, the "what" started taking shape. What features did StepCode absolutely need? I kept it focused:
- The Basics: Variables, assigning values, getting input, showing output.
- Making Decisions:
IF/THEN/ELSElogic, naturally includingELIF(orSI/ENTONCES/SINO/SINO SI). I also addedCASE(SEGUN) statements for multi-way choices despite I hate this type of statement. - Loops:
WHILE(MIENTRAS),FOR(PARA), andREPEAT/UNTIL(REPETIR/HASTA QUE). - Structured Programming: Breaking code into reusable chunks using
PROCEDURE(SUBPROCESO) andFUNCTION(FUNCION). - Data Types: Keeping it simple with basics like
INTEGER(ENTERO),REAL,STRING(CADENA), andBOOLEAN(LOGICO).
The final decision was to select if it would be a compiled or an interpreted language. Think of it like a spoken language translator. An interpreter program reads StepCode line by line and performs the actions immediately. This is different from a compiled language (like C++) where a compiler translates your entire code into machine instructions first, creating a separate executable file.
It's generally simpler to build an interpreter, and it gives that immediate feedback which is great for learning. The interpreter would transform the statements to Javascript that could be run on the browser.
Designing the Syntax
Once you know what your language should do, you need to decide how people will write it. This is the syntax; the grammar, the keywords, the symbols.
For StepCode, I took inspiration from Pascal. It's known for being quite readable, structured, and often used in educational settings, so it was a great choice. On the other hand, the ANTLR4 grammar of Pascal was already available on GitHub, so I had a great base to start.
Now, about that bilingual thing. How do you make IF and SI mean the same thing? This is where designing the grammar carefully comes in. When we define the "IF" keyword for our language rules, we simply tell the parser, "Hey, if you see the text 'IF' OR the text 'SI', treat it as the start of an if-statement." It looks something like this in the grammar definition file we'll talk about later:
IF: 'SI' | 'IF'; // Treat 'SI' or 'IF' as the IF token
WHILE: 'WHILE' | 'MIENTRAS'; // Same idea for WHILEExample of grammar definition
Pretty neat, right? I also decided to make StepCode case-insensitive. IF is the same as iF. Pseudocode is often handwritten or typed informally and this just removes a potential frustration point for learners.
Making Sense of the Code
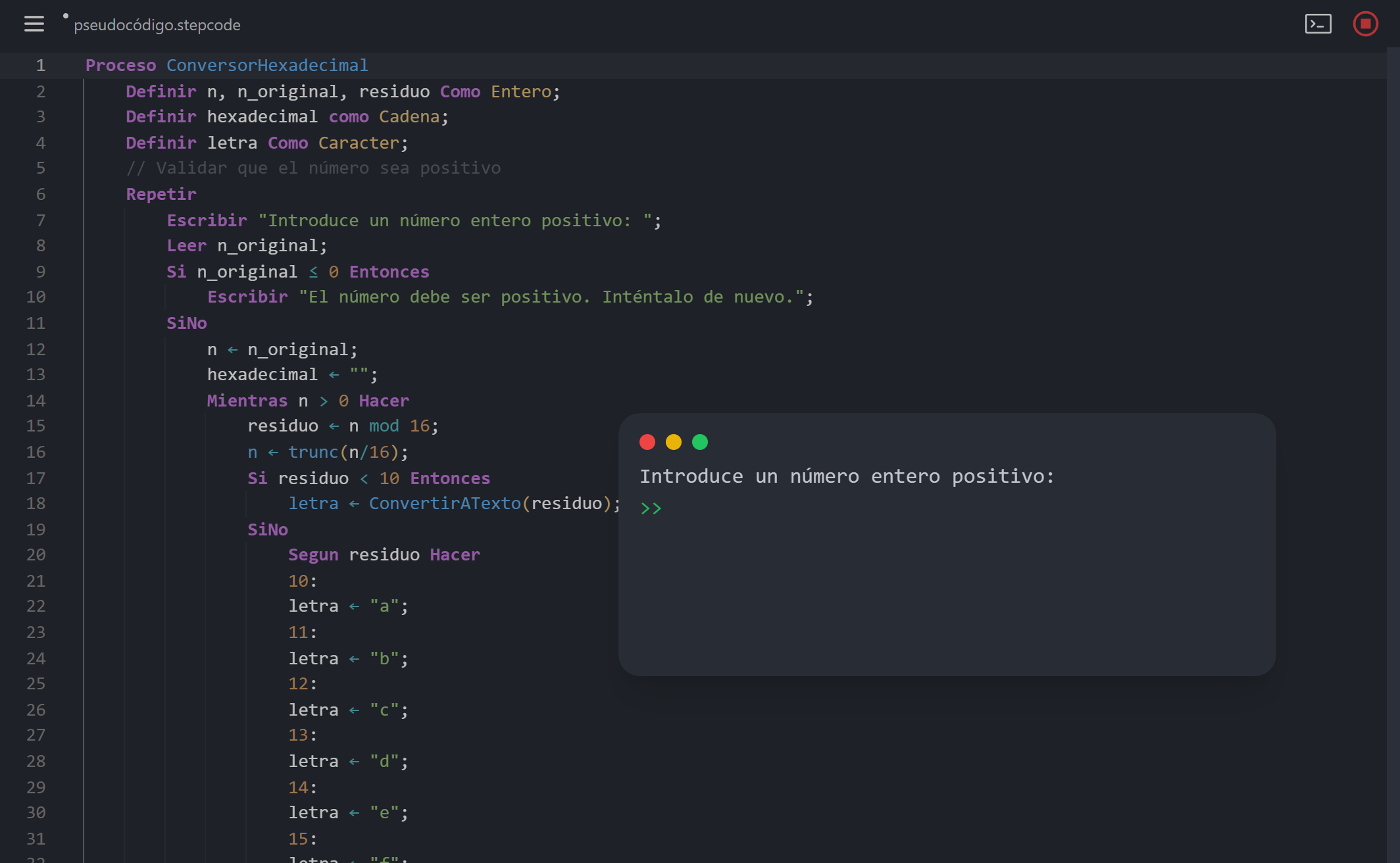
Okay, so we have a language design. How does the computer actually understand code written in StepCode? If someone writes:
PROCESO Saludo
DEFINIR nombre COMO CADENA;
ESCRIBIR "Como te llamas?";
LEER nombre;
SI nombre == "mundo" ENTONCES
ESCRIBIR "Hola, mundo!";
SINO
ESCRIBIR "Hola, ", nombre, "!";
FINSI
FINPROCESOStepCode Snippet
How does that turn into actions? This is where parsing comes in. It’s a two-step process, usually:
- Lexing (or Tokenizing): Breaking the raw text into meaningful chunks, called tokens.
PROCESObecomes aPROGRAM_KEYWORDtoken,Saludobecomes anIDENTIFIERtoken,DEFINIRbecomes aDEFINE_KEYWORDtoken, nombre anotherIDENTIFIER,==anEQUALS_OPERATOR,` "Hola, mundo!"aSTRING_LITERAL, and so on. It's like identifying the words and punctuation in a sentence. - Parsing: Taking that stream of tokens and checking if they form valid "sentences" according to the language's grammar rules. Does a
DEFINEkeyword follow the rules we set? Does anIFstatement have aTHENand anENDIF? The parser usually builds a tree structure (an Abstract Syntax Tree or AST) that represents the code's logical structure.
Now, writing a lexer and parser from scratch? You can do it, but trust me, it's complex. Handling operator precedence (should * happen before +?), nested structures, and all the grammar rules correctly is tricky and error-prone.
This is where tools called parser generators are lifesavers. And one of the most popular ones is ANTLR4 (ANother Tool for Language Recognition).

Here’s the deal with ANTLR4:
- You write a grammar file (usually ends in .g4). This file is where you define all the rules of your language, both the lexer rules (what tokens look like) and the parser rules (how tokens fit together).
- You run the ANTLR4 tool on your .g4 file.
- ANTLR4 magically generates source code (in Java, Python, C#, JavaScript, etc.) for a lexer and a parser that specifically understand your language.
Generating the Grammar
Think of writing a grammar file as teaching ANTLR4 the rules of your language, piece by piece. It needs to know two main things:
- What are the basic words and symbols? (These are the tokens, defined by Lexer Rules)
- How can these words and symbols be combined legally? (These are the syntax structures, defined by Parser Rules)
It's kind of like teaching English: first, you learn the alphabet and basic words (tokens), then you learn how to form sentences and paragraphs (parser rules).
When I started writing the StepCode.g4 file, I thought about the overall structure of a StepCode program. What's the absolute biggest container? Well, a program might have some functions or procedures defined, then the main part of the program, and maybe more functions/procedures after that.
So, the very first rule I wrote (or at least thought about) looked something like this conceptually:
// This is the main entry point, the biggest rule
program: subprogram* main subprogram* EOF;(Simplified slightly for explanation)
Let's break that down:
- program: This is the name I gave to the rule representing the entire program. Rule names usually start with a lowercase letter.
- main: This means "match exactly one instance of whatever the main rule defines". Every program needs a main part where there is code to run.
- subprogram*: This means "match zero or more (*) instances of whatever the subprogram rule define. In this example zero or more procedures or functions can appear before the main part.
- EOF: This is crucial! It means "End Of File". This tells ANTLR that a valid program must consume all the input text. Without it, ANTLR might happily parse just the first valid part of a file and ignore the rest, even if the rest is junk.
See how we started with the overall structure and used placeholders (subprogram, main) for the smaller pieces? This is called a top-down approach, and it's often a good way to start. Now, we need to define those smaller pieces.
Defining the Parser Rules (Statements)
Let's look at how main might be defined:
main: programHeading block ENDPROGRAM;Okay, simple enough. A main section consists of:
- programHeading: Another rule we need to define (e.g.,
PROGRAM MyAlgoorPROCESO MiAlgoritmo). - block: The actual code block (declarations, statements). Another rule to define!
- ENDPROGRAM: This is different! It's in ALL CAPS. By convention, that means it's a Token – one of the basic words defined by the Lexer. In this case, it matches the literal text
ENDPROGRAM(orFINPROCESO, etc., as we'll see).
Now let's tackle a more interesting structure, like an if statement:
ifStatement: IF expression THEN compoundStatement (elseStatement?) ENDIF;
// And maybe the else part:
elseStatement: ELSE compoundStatement;(Simplified slightly for explanation)
Here we see more patterns:
- IF, THEN, ELSE, ENDIF: These are Tokens (keywords). The parser expects to see these specific words.
- expression, compoundStatement, elseStatement: These are other parser rules we need to define. An expression might be something like x > 10, and a compoundStatement would be a sequence of actual programming statements.
- (elseStatement?): The parentheses group elseStatement, and the ? makes that whole group optional. An if statement doesn't require an else part.
How about defining a list, like declaring multiple variables?
variableDeclaration: identifierList AS type_; // Using other rules
DEFINE variableDeclaration SEMI; // Putting it together
identifierList: identifier (COMMA identifier)*; // The list itselfLet's dissect identifierList:
- identifier: Match one instance of the identifier rule (which will match variable names).
- (COMMA identifier)*: This part is grouped by parentheses. The * means "match the stuff inside the parentheses zero or more times". The stuff inside is a COMMA token followed by an identifier. So, this whole rule matches one identifier, optionally followed by commas and more identifiers (like x, or x, y, or x, y, z).
Defining the Lexer Rules (Tokens)
Okay, we've seen parser rules use ALL CAPS names like IF, ENDPROGRAM, COMMA. Where do those come from? They come from the Lexer Rules, which usually appear after the parser rules in the .g4 file. Lexer rules define the basic tokens.
- ('A'..'Z'): Must start with an uppercase letter (or lowercase if case-insensitive). .. defines a range.
- ('A'..'Z' | '0'..'9' | '_')*: After the first letter, can have zero or more (*) letters OR (|) digits OR underscores.
Ignoring Stuff (Whitespace and Comments): This is super important! You don't want spaces or comments cluttering up your parser tokens.
// Match one or more spaces, tabs, newlines and 'skip' them (don't create a token)
WS : [ \t\r\n]+ -> skip ;
// Match // followed by any characters except newline, then skip
COMMENT_1 : '//' ~[\r\n]* -> skip ;The -> skip command tells the lexer: "Yes, recognize this pattern, but then just throw it away. Don't pass it to the parser." In this case, we drop everything after a double slash //.
Operators and Punctuation: Simple mappings.
ASSIGN : ':=' | '<-' | '\u2190' ; // Allow := OR <- OR the ← symbol
SEMI : ';' ;
PLUS : '+' ;
LPAREN : '(' ; // Left parenthesisLiterals (Numbers, Strings): These also match patterns.
NUM_INT : ('0'..'9')+ ; // One or more ('+') digits. Matches 1, 123, 0.
// Matches things like 'Hello world' or "It's okay"
STRING_LITERAL : '\'' ( '\'\'' | ~'\'' )* '\'' // Single quotes
| '"' ( '""' | ~'"' )* '"' ; // Double quotes
// This looks complex! It handles escaped quotes ('') inside strings.
// ~'\'' means "any character that is NOT a single quote".Identifiers (Variable Names, etc.): These follow a pattern. Usually letters, maybe numbers and underscores after the first letter.
// Matches typical variable names like MiVariable, contador1, etc.
IDENT : ('A'..'Z') ('A'..'Z' | '0'..'9' | '_')* ;Keywords: These are usually the simplest. You map the literal text to the token name. Remember our bilingual goal?
PROGRAM : 'PROCESO' | 'ALGORITMO' | 'PROGRAM' ; // A PROGRAM token matches any of these strings
IF : 'SI' | 'IF' ;
THEN : 'THEN' | 'ENTONCES' ;
DEFINE : 'DEFINIR' | 'VAR' ; // Allowing 'VAR' too
ENDPROGRAM : 'FINPROCESO' | 'FINALGORITMO' | 'ENDPROGRAM' ;So the PROGRAM token is recognized if the lexer sees the exact text PROCESO or ALGORITMO or PROGRAM. (Remember it is case insensitive, so it matches program, Proceso, etc. too!).
Walking the Tree
So, ANTLR4 has done its job. It's taken the StepCode source code, used the .g4 grammar, and produced an Abstract Syntax Tree (AST). But an AST is just a data structure, a tree representation of the code. It doesn't do anything by itself. How do we actually execute the logic?
This is the job of the interpreter. And a common way to build an interpreter, especially when using ANTLR4, is using the Visitor pattern.
ANTLR4 automatically generates a base Visitor class (like StepCodeBaseVisitor in our case) with empty methods for each rule in your grammar (e.g., visitIfStatement, visitAssignmentStatement, visitWhileStatement). Our job is to create our own class that inherits from this base visitor and override those methods, filling them with the logic to actually execute that part of the code.
Here’s how it might work:
- visitAssignmentStatement(ctx): When our visitor reaches an assignment node in the AST (like x := 10):
- It needs to figure out the value on the right side. So, it calls visit() on the expression part of the node. This might involve visiting other nodes (like number nodes or variable nodes) until a final value is calculated (e.g., 10).
- It needs to know where to store this value. It gets the variable name (x) from the node.
- It looks up x in a symbol table (we'll get to that) and stores the calculated value (10) there.
- visitIfStatement(ctx): When it encounters an IF node:
- It first visits the expression part (the condition) to evaluate it to true or false.
- If the result is true, it then tells the visitor to proceed and visit the nodes inside the THEN block (visit the
compoundStatement). - If the result is false, it checks if there's an ELSE or ELIF block. If yes, it visits that block; otherwise, it does nothing further for this IF statement.
- visitWriteStatement(ctx): This one's relatively simple. It visits the expression(s) inside the WRITE (ESCRIBIR) command to get their values, and then it prints those values to the console.
Let's remember the how was structured an if statement:
ifStatement: IF expression THEN compoundStatement (elseStatement?) ENDIF;
Here is the visitor implementation when the interpreter finds it:
visitIfStatement = async (ctx: IfStatementContext) => {
const expression = await this.visit(ctx.expression()) as ExpressionReturnType
if (expression.value) {
return await this.visit(ctx.compoundStatement())
} else {
if (ctx.elifStatement()) {
return await this.visit(ctx.elifStatement())
}
if (ctx.elseStatement()) {
return await this.visit(ctx.elseStatement())
}
}
return {
identifier: `${expression.identifier}`,
}
}As you can see, it first evaluates the expression. If the value of the expression is truthy it will visit the compoundStatement and return its result, otherwise it will check if there is and else or elif statement, in if so, visit it.
The Symbol Table
The interpreter needs to remember things, mainly variables and functions/procedures. Where do they live? In a symbol table (sometimes called an environment or symbol map). Think of it like a dictionary or an address book where the interpreter stores variable names and their current values, or function names and their definitions.
This is also where scope comes in. When you define a variable inside a PROCEDURE, it should only exist inside that procedure, right? It shouldn't clash with a variable of the same name outside it. The symbol table implementation needs to handle this, usually by creating nested scopes or linked environments. When looking up a variable, the interpreter checks the current local scope first, then the scope outside it, and so on, up to the global scope.
For StepCode, handling DEFINE identifierList AS type_ meant the visitor needed to add those identifiers to the current scope in the symbol table. I also had to decide about types. StepCode defines types (AS INTEGER, COMO CADENA). For StepCode, I opted for dynamic checks during interpretation, so if you try to add a number and a string, the interpreter would raise a runtime error. Handling BYVALUE (POR VALOR) vs. BYREFERENCE (POR REFERENCIA) parameters also required careful management in the symbol table and how function calls passed arguments (copying the value vs. passing a reference to the original variable).
This "walking the tree" and manipulating the symbol table is the heart of the interpreter. It's where the static structure of the code becomes dynamic execution.
The Most Difficult Part
Building StepCode wasn't always a walk in the park. You hit snags, solve puzzles, and learn a lot. Some challenges were more "interesting" than others.
ANTLR4 Grammar Puzzles:
- Ambiguity: Every now and then, ANTLR4 would complain about an ambiguous grammar. This means there was more than one way to interpret a sequence of tokens according to the rules I'd written. Usually, this happened with complex expressions. Fixing it often involved restructuring the grammar rules to be more specific about precedence or structure.
- Evolution: As StepCode grew, the grammar needed updates. Adding a new feature sometimes meant rethinking existing rules to make sure everything still fit together logically.
I really recommend you to install the ANTLR extension to see your AST in real time to sort these problems.
Interpreter Logic Headaches:
- Scope: Getting variable scope right, especially with nested procedures or functions, is famously tricky. Making sure variables were accessible where they should be, and hidden where they shouldn't, required careful design of the symbol table and how scopes were managed during function calls and returns.
- Runtime Errors: ANTLR4 is great for catching syntax errors ("You forgot a semicolon!"). But what about errors that only happen when the code runs? Like trying to use a variable that hasn't been defined (Variable 'x' not defined), dividing by zero, or adding text to a number (Type mismatch). The interpreter needs to detect these during execution and report them clearly. Making error messages helpful, especially for learners, is crucial but often overlooked. "Error on line 15" isn't nearly as good as "Error on line 15: Cannot add the text 'Hello' to the number 10."
- Control Flow Statenebts: Implementing things like
BREAK(ROMPER) to exit a loop early,CONTINUE(CONTINUAR) to skip to the next iteration, orRETURN(REGRESAR) from a function required special mechanisms. You can't just stop visiting; you need a way to signal back up the chain that the normal flow is being interrupted. Often, this involves using special return values or even exceptions within the interpreter itself. - The Bilingual Thing: When the language evolved, I discovered there were some conflicts between Spanish tokens and English tokens.
So, what was the hardest part? Probably getting the scope management and runtime error handling really robust, indeed I left the project without fully fixing this.
The Bottom Line
So, there you have it. A whirlwind tour of building a pseudocode interpreter, using StepCode as our guide.
Building something like StepCode isn't just about the final program. It’s about the journey. I gained this incredibly deep appreciation for how the languages we use every day actually function under the hood. Suddenly, concepts like parsing, abstract syntax trees, and interpreters aren't just academic terms; they're tools I've actually used.
If any part of this sparked your curiosity, I wholeheartedly encourage you to try building something small yourself, and contribute to StepCode. Now with AI it must be easier than never.
We can create the best Pseudocode interpreter out there together!
Want to Dig Deeper?
If you're interested in exploring this further, here are some fantastic resources:
- ANTLR4: The official website (antlr.org) has documentation, downloads, and examples. The "ANTLR Mega Tutorial" is also often recommended.

- "Crafting Interpreters" by Robert Nystrom: This book is simply amazing. It walks you through building two complete interpreters (one tree-walk interpreter in Java, one bytecode VM in C) with incredibly clear explanations.
- StepCode Project: Finally, if you can contribute with the project. You can checkout the repo. You can collaborate at the language (interpreter) or the online editor (IDE)
I hope you to see you soon in my next blog entry!
If you enjoy the content, please don't hesitate to subscribe and leave a comment! I would love to connect with you and hear your thoughts on the topics I cover. Your feedback is greatly appreciated!