Creating Offline-First Applications
Offline-first web apps: architecture, client-server vs. offline, data synchronization, consistency models (causal consistency). Build responsive, local-like apps


During the last few years a new application paradigm has become popular: Offline-first applications. Offline-first applications are web applications that feel like local applications in interactivity and responsiveness.
Lately I have been involved with this development approach meanwhile I was implementing Bezier, a tool for writing system documentation, and after months diving into it, I would like to share with you how this type of system works.
This weekend I'm working on integrating the multiple modules I have implemented into the project environment. Bezier is taking shape! pic.twitter.com/acaERUOzUd
— Rolando Andrade 🌎 (@RolandoAndrade_) April 6, 2024
The Client-Server Architecture
Most of the web applications follow a Client-Server architecture where the user interacts with a page in the browser, and the page executes calls to an external server to execute some operations like storing data on a database, or making a processing operation.
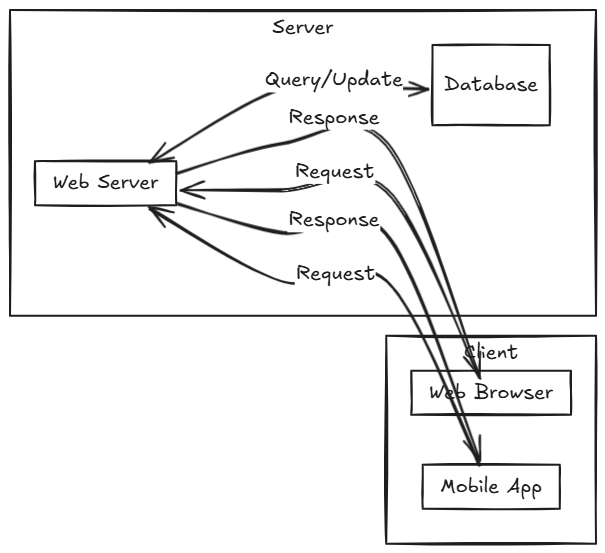
This architecture has led the design of applications during all this time, almost all the web applications and even desktop and mobile applications you are using today are implemented under a variation of this paradigm.
Due to its distributed nature, this approach faces the common pitfalls of distributed systems, including latency, ensuring data consistency, and guaranteeing system uptime.
Latency
Latency means the time of sending a message from one site to another, for example, to register an user, the browser makes a request to the server, the server sends the request to the database, and then the response is routed back. Most of the time of those requests are not processing time, it is latency, that's why on localhost we almost have no wait times on request meanwhile in remote environments we have to wait 100-500ms for responses.
To represent this time, developers usually block the UI and put a loader to tell the user something is being processed. After certain time, the loader stops and the user can continue using the application.

Integrity
Now imagine you have two clients editing the same data like a filesystem. If user A decides to delete the file foo.txt, and the user B does not see the change. The system stops being reliable and if the user B tries to access the deleted file likely he will receive an error.
This type of error is related to consistency and integrity of the data. To handle this developers usually have to implement some integrity services, and use heavy reliable infrastructure.
Availability
Now imagine the application just go offline. It does not work anymore. Most of the time developers will show a message Something went wrong. Try again later or something like that, but the user is unable to continue using the application.
Do you imagine if you could not use applications like Google Docs, just because you lost the connection? It would be awful, and it can be done offline, so why not delegating the writing process to the client instead of doing it on the server?
Presenting Offline-First Applications
Offline-first applications resolve most of the problems related to distributed systems by adding more complexity on the data layer and backend services.
The idea of this approach is to remove the dependency of the server to allow the application work, by storing the mutations and changes locally and send them as soon as the server is available again.
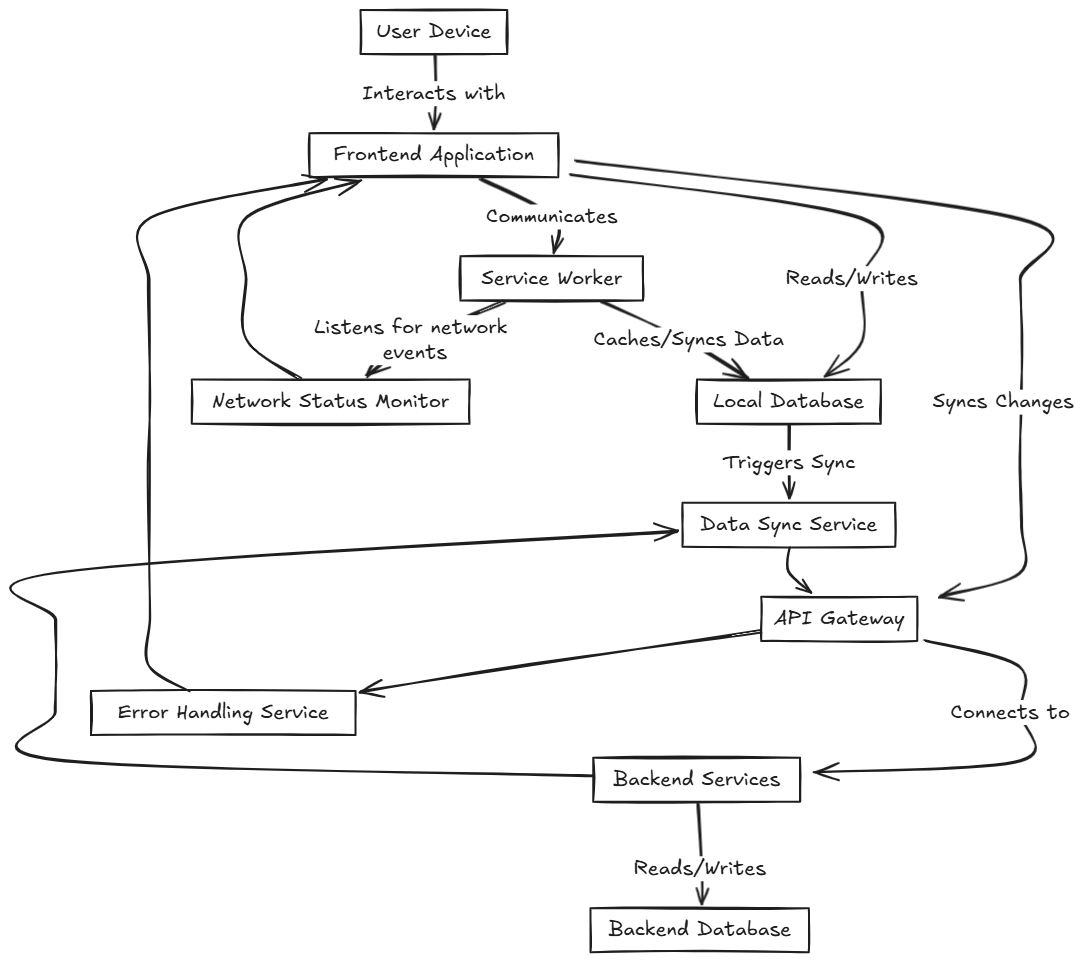
How do Offline-First Applications work?
Explaining how this framework works, is better with an example, so let's take my application, Bezier. A tool for writing beautiful documentation and design systems with diagrams.
Client Side
The first time the user enters to the workspace, the client gets from the server the website, and it executes certain scripts to persist the data locally in the browser. From now on, the main database for the client application is the IndexDB of the browser, the frontend gets all the data from here.
When the user makes a change, for example, create a new project (Story), it triggers a mutator. A mutator is a service that makes the write operations on the database, and enqueues the mutations in a synchronization service, performing an optimistic update. An optimistic update is an operation that executes the transaction without considering the future response, so in this case, it creates the project immediately for the user, and the user can interact with it meanwhile the backend is processing the request or even before receiving it!
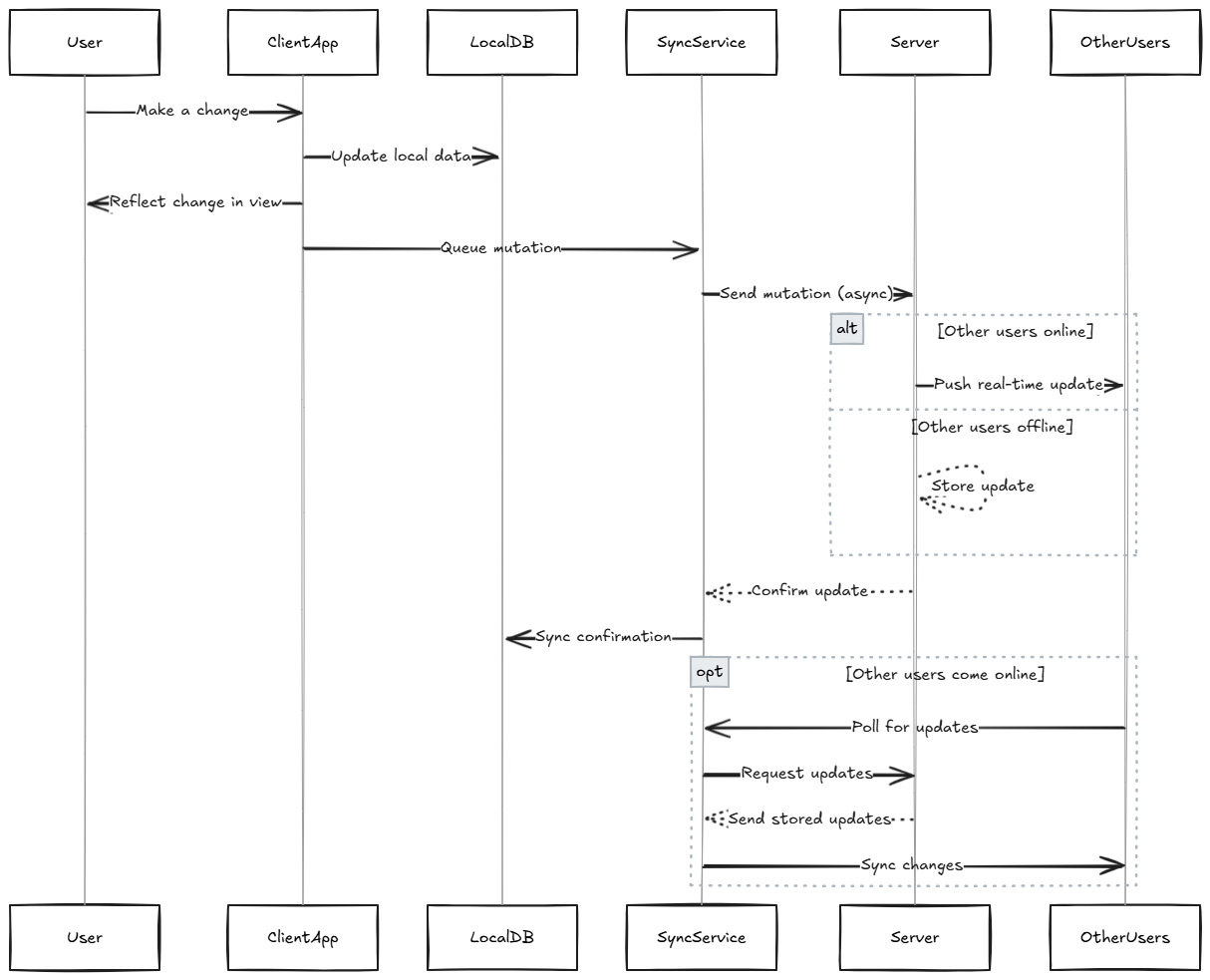
The sync service is compounded by three elements, a polling service that makes requests to the server every X seconds to pull new data, a message service that receives async messages using tools like Pusher to detect changes from other clients in real-time, and a push service that send all the queued mutations.
Let's suppose a team member was connected in the same workspace at that time. If that user is online, the system would receive a real-time pusher event and the sync service would mutate the database and refresh the view, so since the frontend reads from the local database, it will show the new project created. If the user was offline, once he is online again, the polling service will receive a response from the server with the changes made, then it updates the local database and trigger a view refresh.
Server Side
One of the drawbacks of this architecture, is that the implementation of the backend services is highly tied to the sync service. Of course you can decouple the business services, but the data model must be updated to add some fields, and most of the updates must be done through a controller instead of using different endpoints, since the polling service on clients make request to this endpoint every X seconds.
There are four main strategies to pull and push data on this paradigm: Reset, Global Version, Per-Space, and Row Version. You can learn more about them on the documentation of Replicache, but I will write more articles about them in the future, for now here is a brief description:
- Reset Strategy: It is similar to a PUT operation. Every time a client make a change, push everything to the database to replace the existing version of all the resources with a new one. Other clients, pull all the changes too. This means, waste of resources, but quite easy implementation.
- Global Version Strategy: We add a field on the mutable entities to indicate the current version of the entity. After a change, we add one to that field, and all the clients sync their data starting from the last version. All data is synced to all users, so this means we cannot have private workspaces or channels.
- Per-Space Strategy: Additionally to the version field of the last approach, we add another field to identify the workspace of the resource. This way, if a user in workspace W makes a change, users on workspace X do not pull changes since they were filtered by space.
- Row Version Strategy: It uses an artifact named Client View Records (CVRs). Those are structures that contains all the data that is seen by a client at a given time. So if there is a change, it can be computed comparing the last and new CVR.
On Bezier I used a Per-Space Strategy, since it seemed the most indicate for the task and its simplicity. The outline of the implementation is something like this:
Pushing Data
- Verify the client belongs to the workspace.
- Increase the mutations version for the client (changes made by the client) and client group.
- Add the mutation increasing one to the mutation version for that resource and workspace.
- Call the message service (Pusher) to notify of the change to all the subscribed clients.
Pulling Data
- Client makes a pull request with its current version (changes made by the client).
- Verify the client belongs to the workspace.
- Get all the records of that space that has a greater version than the current version.
- The client updates its data and its current version.
We will see this deeper on future posts. For now it is a good approach to the topic, and show you how you manage versions of a resource that can be shared across many clients.
Consistency
You might be wondering about potential conflicts. Conflicts are a common occurrence in any system, and this one is no exception. While there are various consistency models, Causal Consistency is one of the most robust and is the approach used by Replicache, the library I used in Bezier and as reference for this post.
Causal consistency is a model that guarantees that operations that are logically connected will be observed in the same sequence by all processes within a system. This means that if one operation is dependent on another, all processes will see them in the correct order.
Here is an example scenario:
- User A creates a document titled "Document 1" and adds a few points.
- User B also creates a document titled "Document 1" and adds a different set of points. Since A and B are the same operation, the systems agree that there is a redundant operation and updates the local system with the created one on the server.
- User A and User B both edit their documents offline.
- When the devices reconnect, the app uses causal consistency to determine the correct order of operations and merge the changes.
- The final document might include both sets of points, or remove one.
They key here, is having just atomic operations put , and delete. This way operations are easily mergeable and can be ordered in time by its dependencies when the last version field do not allow to identify what was the first mutation.
The Bottom Line
Today we learned the basics of how offline-first applications work and some important concepts for implementation and design. In future post I will extend this topic to explain in a deeper way all the things related to the strategies to push and pull data, and expand the theory about consistency models focused on distributed systems.
For now, just have a great week and see you in the next posts!
If you enjoy the content, please don't hesitate to subscribe and leave a comment! I would love to connect with you and hear your thoughts on the topics I cover. Your feedback is greatly appreciated!